Explain the Document Object Model (DOM) for parsing XML documents.
Document Object Model and XML Parsing
The Document Object Model (DOM) is a W3C specification. It defines interfaces that enable applications to access the structure and contents of an XML document. XML parsers that support the DOM specification implement these interfaces. When a DOM parser is used, the output produced is a tree-like structure that contains all of the elements included in the input XML document.
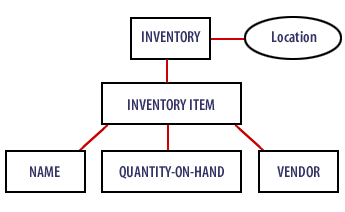
DOM document Tree Structure
Given the XML document below:
The following tree structure would be produced by a DOM parser.
Document tree structure from DOM parser
DOM Java Interfaces
The DOM defines many Java interfaces. Here is a list of the commonly used ones:
Node: represents a single node in the document tree
Element: represents an XML element
Attr: represents an attribute of an element
Text: represents the actual contents of an element or attribute
Document: represents the entire input XML document
DOM methods: The DOM provides many methods that may be used to process an XML document. Some of the commonly used methods of the DOM model include the
following:
Document.getDocumentElement(): returns the element of the document object, namely the root element
Document.getElementById("id"): returns the element in the XML document with the given id
Document.getElementByTagName("tagname"): returns all the elements in an XML document with the given tagname
Node.getFirstChild(): returns the first child of this node.
Node.getLastChild(): returns the last child of this node
Node.getNextSibling(): returns the node immediately following this node
The following series of images shows the parser API used to parse XML.
Parser API used to parse XML
1. Create a parser object instance based on a DOM parser
2. Invoke the parse method on the parser object to actually parse the content of the
XML document named "orders.xml"
Line 3:
3. Invoke the getDocument() method of the parser object to return a Document
object name "document". The document object contains the entire parsed contents of the document
4. Using the getElementByTagName() method of the document object,
we obtain a list of all elements in the XML document with the name
"INVENTORY-ITEM."
Java Code to parse an XML Document
Here's an example of Java code that uses the DOM API to parse an XML document:
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
import java.io.File;
public class XMLParser {
public static void main(String[] args) {
try {
File inputFile = new File("input.xml");
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(inputFile);
doc.getDocumentElement().normalize();
System.out.println("Root element :" + doc.getDocumentElement().getNodeName());
NodeList nList = doc.getElementsByTagName("student");
System.out.println("----------------------------");
for (int temp = 0; temp < nList.getLength(); temp++) {
Node nNode = nList.item(temp);
System.out.println("\nCurrent Element :" + nNode.getNodeName());
if (nNode.getNodeType() == Node.ELEMENT_NODE) {
Element eElement = (Element) nNode;
System.out.println("Student roll no : "
+ eElement.getAttribute("rollno"));
System.out.println("First Name : "
+ eElement
.getElementsByTagName("firstname")
.item(0)
.getTextContent());
System.out.println("Last Name : "
+ eElement
.getElementsByTagName("lastname")
.item(0)
.getTextContent());
System.out.println("Nick Name : "
+ eElement
.getElementsByTagName("nickname")
.item(0)
.getTextContent());
System.out.println("Marks : "
+ eElement
.getElementsByTagName("marks")
.item(0)
.getTextContent());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
This code uses the javax.xml.parsers package to parse an XML document called "input.xml". The code creates a DocumentBuilderFactory, and uses it to create a DocumentBuilder. The parse method of the DocumentBuilder is then used to parse the XML document and create a Document object.
The code then uses the DOM API to traverse the elements in the Document and access the data contained within the elements. The code prints out the values of the elements and their attributes, such as the roll number and names of students in the XML document.
The next lesson explains the Simple API for XML (SAX) model for parsing XML documents.